
Du kennst das Gefühl. Stunde eins, du bist im Flow. Die App nimmt Form an. Komponenten entstehen, die KI schlägt Namen vor, die du noch besser findest als deine eigenen. Du fühlst dich wie ein Zehnfach-Entwickler. Ordnerstruktur sauber (Teil 1), MCP-Gedächtnis eingebaut (Teil 2), Bad Cop Agent läuft (Teil 3). Was kann noch schiefgehen?
Dann kommt Stunde vier. Die KI fängt an zu taumeln. Sie schlägt eine Library vor, die du vor zwei Stunden schon als inkompatibel verworfen hast. Sie nennt eine Funktion getUserData – dieselbe Funktion, die sie zehn Prompts vorher fetchUser genannt hat. Und dann, der Klassiker: Sie schreibt "// TODO: implement this later" in Methoden, die du explizit als kritisch markiert hattest.
Willkommen im 80/20-Fluch. Du bist nicht der Erste. Du wirst nicht der Letzte sein.
🧠 Was der 80/20-Fluch physikalisch bedeutet
Jedes Sprachmodell – egal ob Claude, GPT oder Gemini – hat ein sogenanntes Context Window. Das ist der Arbeitsbereich des Modells: alles, was es gleichzeitig "sehen" und berücksichtigen kann. Claude 3.7 hat 200k Token, GPT-5.x arbeitet mit ähnlichen Größenordnungen. Klingt riesig. Ist es auch – bis dein Projekt wächst.
Das Problem heißt Attention Degradation. Mit steigender Kontextlänge sinkt die Fähigkeit des Modells, frühe Informationen mit gleicher Präzision zu gewichten wie späte. Einfach gesagt: Je mehr du in eine Session packst, desto mehr "vergisst" die KI was am Anfang gesagt wurde – selbst wenn es technisch noch im Context steht.
Die Schwelle liegt in der Praxis bei etwa 20.000–30.000 Token pro Session – das entspricht ungefähr 15 bis 20 aktiven Dateien, die gleichzeitig im Chat referenziert wurden. Danach:
- Schreibstil wechselt unbemerkt (camelCase → snake_case)
- Libraries werden empfohlen, die schon als inkompatibel ausgeschlossen wurden
- Bestehende Hilfsfunktionen werden reimplementiert statt wiederverwendet
- Kritische Methoden bekommen
// TODO-Platzhalter statt echter Implementierung - Die KI bejaht alles, auch widersprüchliche Anforderungen
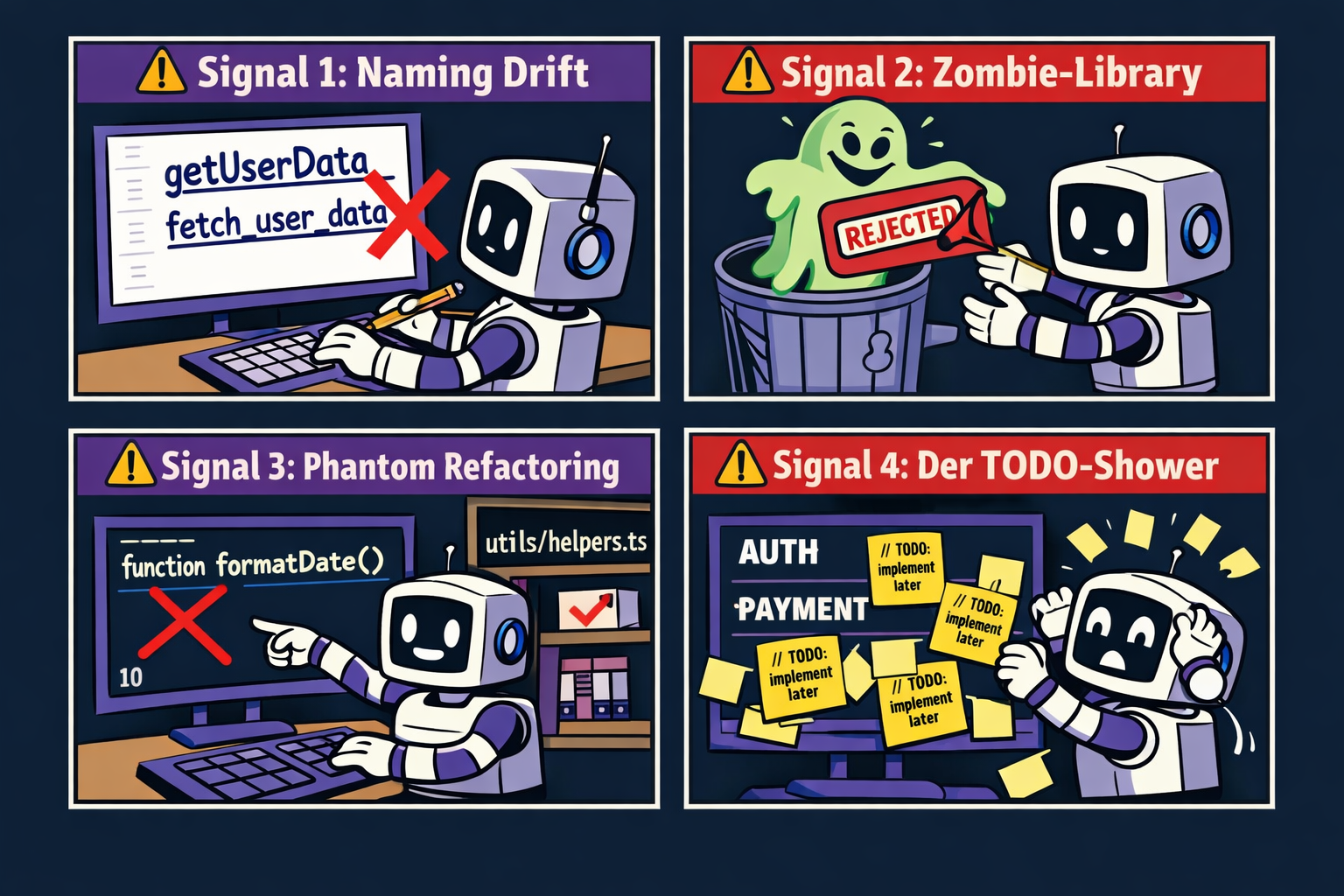
🔥 Die 4 Warnsignale – erkenne den Fluch bevor er zuschlägt
Der 80/20-Fluch kündigt sich an. Wer die Signale kennt, kann gegensteuern bevor der Schaden entsteht:
Signal 1 – Der Naming-Drift: Die KI wechselt Konventionen ohne Ankündigung. Du siehst in derselben Datei getUserProfile() und fetch_user_profile(). Das Modell hat die Naming Convention vom Anfang der Session aus den Augen verloren.
Signal 2 – Die Zombie-Library: Die KI empfiehlt eine Dependency, die du vor einer Stunde explizit ausgeschlossen hast – mit Begründung. Wenn das passiert, ist der Anfang der Session für das Modell unsichtbar geworden.
Signal 3 – Das Phantom-Refactoring: "Ich habe die Hilfsfunktion formatDate() für euch erstellt" – obwohl diese Funktion seit Stunde eins in /utils/helpers.ts existiert. Das Modell reimplementiert, statt zu referenzieren.
Signal 4 – Der TODO-Shower: Kritische Logik wie Authentication, Database Validation oder Error Handling wird plötzlich mit // TODO: implement later kommentiert. Das Modell arbeitet im Spar-Modus – es priorisiert Antwortgeschwindigkeit über Vollständigkeit.
🏗️ Die Lösung: AI-friendly Modular Architecture
Die Antwort auf den 80/20-Fluch ist keine neue KI und kein größeres Context Window. Die Antwort ist strategische Dekomposition: Du denkst dein Projekt so auf, dass keine einzelne Session jemals das kritische Schwellgewicht erreicht.
Das bedeutet konkret drei Dinge:
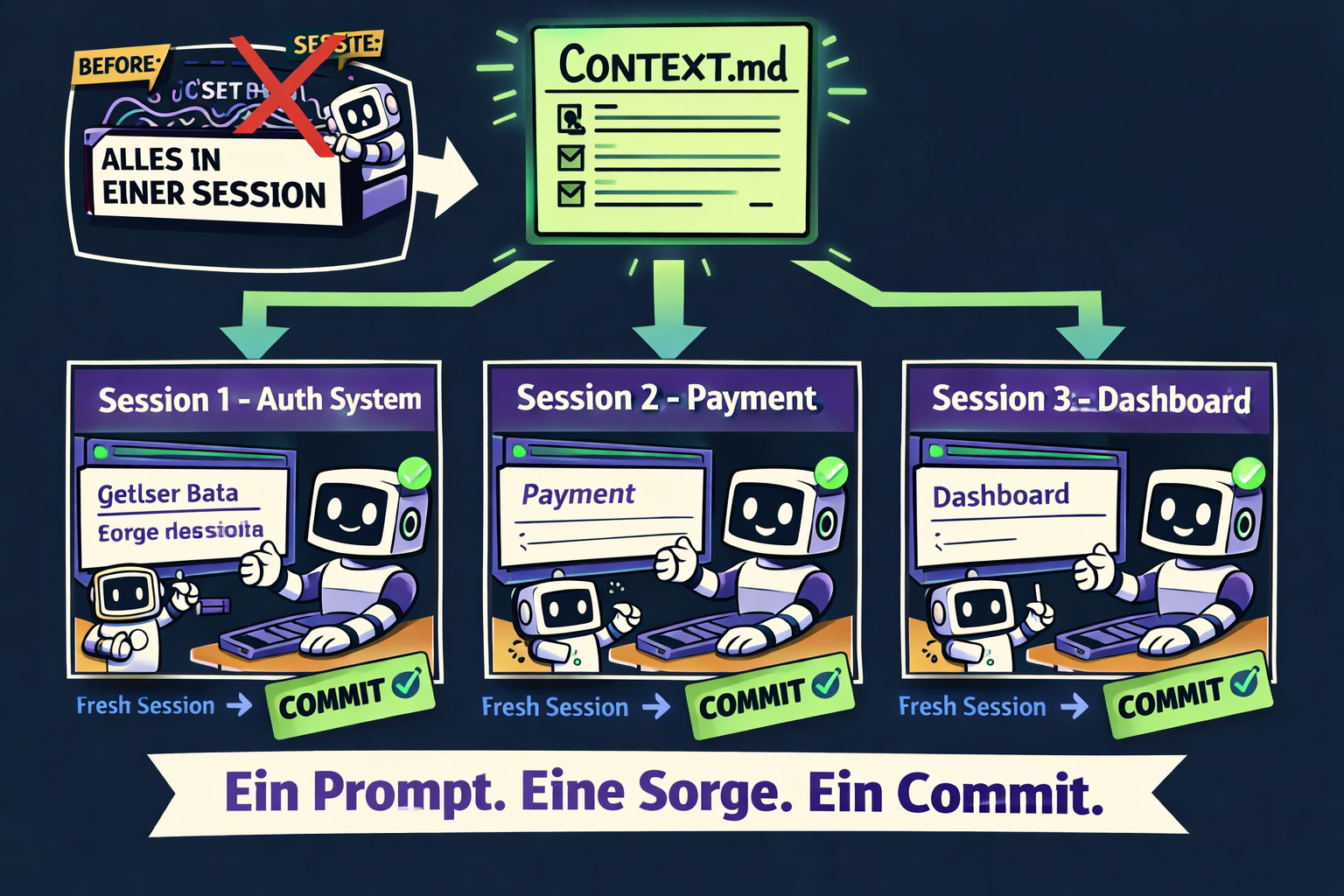
1. Ein Prompt – eine Sorge. "Baue das komplette Auth-System mit JWT, Refresh Tokens, Rate Limiting und Email-Verification in einem Schritt" ist kein guter Prompt – es ist ein Rezept für Context-Kollaps. Zerlege es: Session 1 implementiert nur das JWT-Basis-System. Session 2 fügt Refresh Tokens hinzu. Erst wenn Session 1 getestet und committed ist, kommt Session 2.
2. Die CONTEXT.md – dein Architektur-Anker. Erstelle eine Datei im Root deines Projekts: CONTEXT.md. Diese Datei enthält:
- Tech Stack (mit Versionsnummern, keine Wildcards)
- Naming Conventions (camelCase/snake_case – explizit)
- Bereits implementierte Hilfsfunktionen (Pfad + Kurzbeschreibung)
- Verbotene Libraries (mit Begründung)
- Architektur-Entscheidungen (warum kein Redux, warum Postgres statt MongoDB)
Der erste Prompt jeder neuen Session lautet: "Lies CONTEXT.md. Stelle sicher dass du alle Konventionen, bestehenden Funktionen und Architektur-Entscheidungen kennst, bevor du Code schreibst."
3. Saubere Session-Grenzen. Jede Session endet mit einem Commit. Kein halbfertiges Feature über Nacht im Chat lassen. Wenn du am nächsten Tag weitermachst, startest du mit einem frischen Chat und dem CONTEXT.md-Prompt – nicht mit dem 4-Stunden-Chat von gestern.
Dein BesserAI Context-Reset Prompt (Einfach kopieren)
Füge diesen Block an den Anfang jeder neuen Coding-Session ein – egal ob nach einer Pause, nach einem Commit oder am nächsten Morgen:
Lies zuerst die Datei CONTEXT.md im Root-Verzeichnis dieses Projekts.
Bestätige danach:
1. Tech Stack und Versionen (liste sie auf)
2. Naming Convention (camelCase oder snake_case?)
3. Bereits existierende Hilfsfunktionen (nenne 3 Beispiele)
4. Verbotene Libraries in diesem Projekt (falls vorhanden)
Schreibe erst Code, wenn du diese 4 Punkte bestätigt hast.
[SINGLE CONCERN RULE]
In dieser Session arbeiten wir ausschließlich an: [AUFGABE HIER EINTRAGEN].
Schlage keine Erweiterungen vor, die über diesen Scope hinausgehen.
⏱️ Session-Hygiene: Wann ist der richtige Zeitpunkt für einen Neustart?
Die häufigste Frage: "Wann genau soll ich die Session neu starten?" Hier ist die praktische Antwort, kein Bauchgefühl:
Starte eine neue Session wenn:
- Du eines der vier Warnsignale siehst (Naming-Drift, Zombie-Library, Phantom-Refactoring, TODO-Shower)
- Du gerade einen Feature-Commit gemacht hast – auch wenn die Session noch "ok" wirkt
- Du von Modul A zu einem anderen, unabhängigen Modul B wechselst
- Die Session länger als 3 Stunden aktiv war
- Du merkst dass du anfängst, der KI nicht mehr zu trauen – das Instinkt-Signal ist real
Starte keine neue Session wenn:
- Du mitten in einem Refactoring bist, das halbfertig den Build bricht – commit oder revert zuerst
- Du glaubst, noch 10 Minuten durchzuhalten löst das Problem – tut es nie
🏆 Was Vibe Coding 2026 von Vibe Coding 2024 unterscheidet
In 2024 war Vibe Coding noch ein Experiment. In 2025 wurde der erste Hype desillusioniert – 63% der Entwickler, die rein auf KI-Code setzten, verbrachten mehr Zeit mit Debugging als mit Bauen. In 2026 hat sich eine neue Kategorie herauskristallisiert: der Orchestrator.
Der Orchestrator schreibt selbst wenig Code. Aber er denkt wie ein Architekt: Er zerlegt Probleme in sessiontaugliche Einheiten, hält den Context frisch, kennt die Grenzen seines Werkzeugs – und nutzt sie zu seinem Vorteil.
Simon Willison, einer der einflussreichsten Stimmen in der Dev-Community, hat es auf den Punkt gebracht: "If an LLM wrote code and you reviewed it, tested it, and explained it – that's not vibe coding. That's software development." Und genau das ist das Ziel: nicht blindes Vertrauen, sondern informierte Kontrolle.
Fazit: Die App die du in 4 Stunden Vibe Coding baust, lebt nur wenn du die Physik des Tools respektierst. Context Window Degradation ist keine Fehlfunktion – sie ist eine Eigenschaft. CONTEXT.md, klare Session-Grenzen und der Ein-Prompt-eine-Sorge-Ansatz sind keine Bürokratie. Sie sind der Unterschied zwischen einem Hobby-Projekt das nach drei Tagen stirbt und einem MVP der auf Schiene bleibt.
Teil 5 kommt. Thema: CI/CD ohne DevOps-Kenntnisse – wie du mit GitHub Actions und einem MCP-Server deinen Deploy-Prozess vollständig automatisierst.
Häufige Fragen zum 80/20-Fluch
Ab wann setzt Context Window Degradation konkret ein?
In der Praxis merkst du die ersten Signale zwischen 20.000 und 30.000 Token pro Session – das entspricht etwa 15 bis 20 aktiven Dateien, die im Chat referenziert wurden. Das Schwellwert variiert leicht zwischen Modellen: Claude hält sich bei langen Kontexten länger, GPT-4o-Varianten zeigen Degradation tendenziell früher.
Ist ein größeres Context Window die Lösung?
Nur teilweise. Claude 3.7 mit 200k Token verlängert die Session – aber Attention Degradation setzt trotzdem ein, nur später. Die Architektur-Disziplin bleibt notwendig. Größere Context Windows sind eine Pufferzone, kein Freifahrtschein.
Muss ich nach jedem Commit einen neuen Chat starten?
Nicht zwingend nach jedem Commit – aber nach jedem Feature-Abschluss ist es eine gute Regel. Wenn du von Auth auf Payment-Integration wechselst: neuer Chat, CONTEXT.md neu ankern. Innerhalb desselben Features kannst du weitermachen – solange du keine Warnsignale siehst.
Was wenn mein Projekt schon in diesem Chaos ist?
Audit zuerst. Öffne einen frischen Chat, gib der KI nur die CONTEXT.md (die du jetzt erstellen musst) und bitte sie, den aktuellen Code auf Inkonsistenzen zu scannen. Naming Drifts, reimplementierte Funktionen, TODO-Löcher – das ist der erste Schritt. Dann reparierst du Modul für Modul, in sauberen Sessions.
Quellen: daily.dev – Vibe Coding 2026 · ischemist.com – How Vibe Coding Killed Cursor · Synclovis – BMAD Architecture Playbook · AI Dev Day India – Vibe Coding Governance Rules · Keywords Studios – State of Vibe Coding 2026